Monocular Visual Odometry
Summary
Scale drift is a crucial challenge for monocular autonomous driving to emulate the performance of stereo. This paper presents a real-time monocular SFM system that corrects for scale drift using a novel cue combination framework for ground plane estimation, yielding accuracy comparable to stereo over long driving sequences. Our ground plane estimation uses multiple cues like sparse features, dense inter-frame stereo and (when applicable) object detection. A data-driven mechanism is proposed to learn models from training data that relate observation covariances for each cue to error behavior of its underlying variables. During testing, this allows per-frame adaptation of observation covariances based on relative confidences inferred from visual data. Our framework significantly boosts not only the accuracy of monocular self-localization, but also that of applications like object localization that rely on the ground plane. Experiments on the KITTI dataset demonstrate the accuracy of our ground plane estimation, monocular SFM and object localization relative to ground truth, with detailed comparisons to prior art.
Accuracy
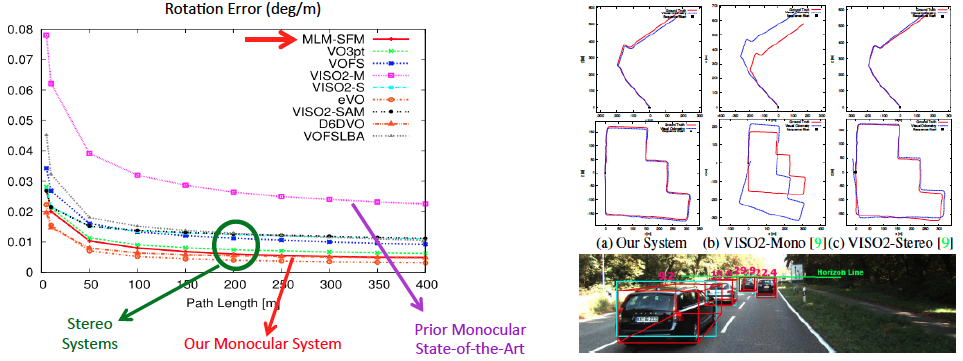
We demonstrate our performance on the KITTI dataset. For camera self-localization, our purely vision-based system achieves a rotation error of 0.005 degrees per meter and a translation error of 2.5%, which compares favorably even to state-of-the-art stereo systems and significantly outperforms other monocular systems. For 3D localization of other traffic participants like cars, we achieve low errors of 8% for near objects (within 30 meters) and 12% for far objects (beyond 30 meters).
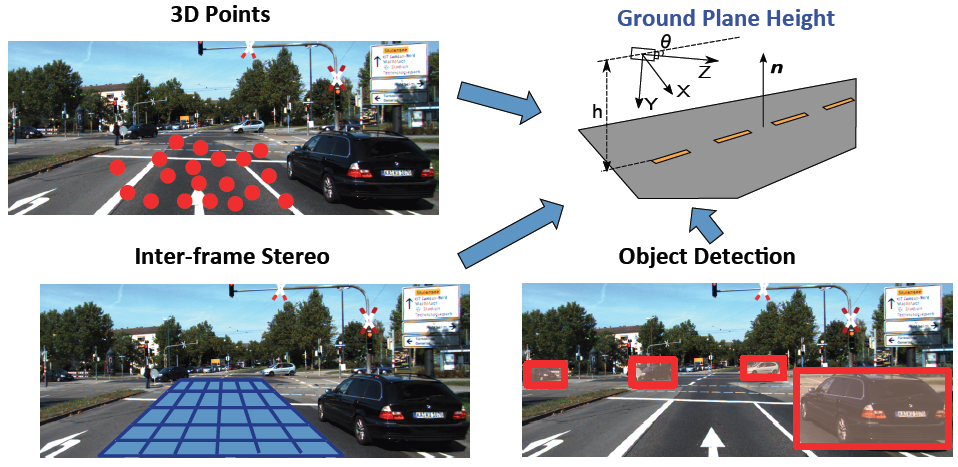
Cue combination
The main challenge in monocular SFM is scale drift, since unlike the case of stereo, there is no reference baseline. We overcome this challenge with a novel cue combination framework, that combines information from 3D points, inter-frame stereo and object detection.
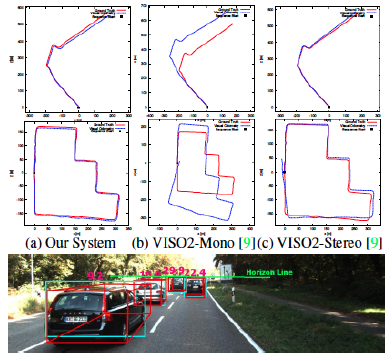
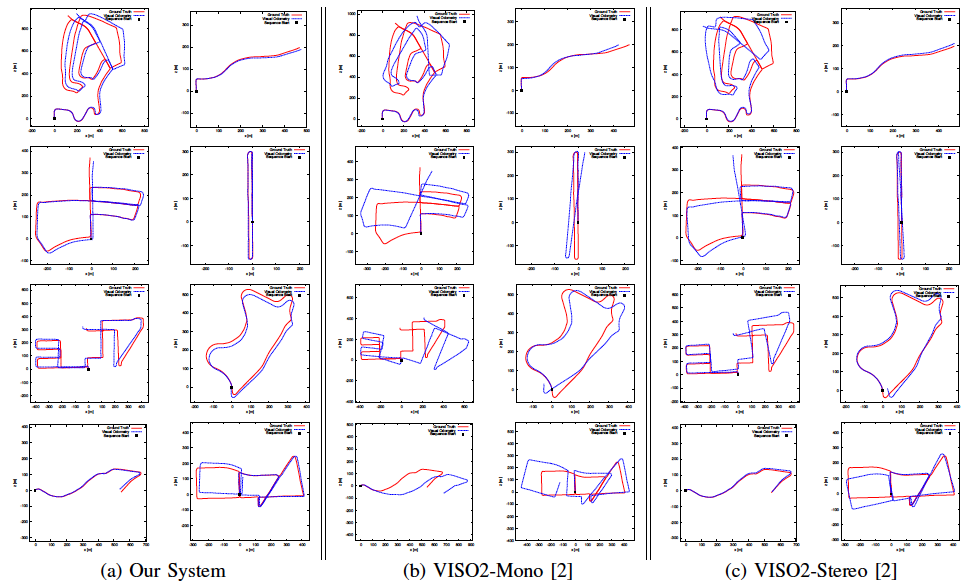
Comparison to other systems
Our real-time monocular SFM is comparable in accuracy to state-of-the-art stereo systems and significantly outperforms other monocular systems. A few example sequences are shown here from the KITTI benchmark.
Videos
These videos provide a 1-minute description of the paper and demonstrate the monocular visual odometry and 3D object localization results.
Overview
3D object localization
Monocular visual odometry
宋适宇
Director of Localization and Mapping
My research interests include Computer Vision, Robotics, Machine Learning, Simultaneous Localization and Mapping (SLAM).